Nie chcę by roboty wyszukiwarek indeksowały moje strony ale nie mam dostępu do kodu witryny aby dodać znacznik metatag robots – co teraz? Odpowiedzią są odpowiednie reguły w pliku .htaccess .
W kwestii blokowania indeksowania, oprócz <meta> tagów mamy jeszcze do dyspozycji lokalny plik konfiguracji serwera Apache w którym już nie raz dodawaliśmy np. przekierowania 301 lub włączaliśmy kompresję gzip – .htaccess.
Noindex plików PDF
Jeśli chodzi o pliki z konkretnym rozszerzeniem (typem), np. PDF, jest na to proste i skuteczne rozwiązanie proponowane przez Google. W ten sposób można dodać „noindex, nofollow” na wszystkie pliki PDF lub pliki graficzne:
# Reguła dla konkretnego typu pliku (PDF):
<Files ~ "\.pdf$">
Header Set X-Robots-Tag "noindex, nofollow"
</Files>
# Reguła dla kilku typów na raz:
<Files ~ "\.(png|jpe?g|gif)$">
Header Set X-Robots-Tag "noindex, nofollow"
</Files>Hola hola! Przecież to nie jest stary dobry metatag „robots” – nie widać żadnych zmian w kodzie strony! Pomińmy fakt, że żaden człowiek nie zagląda do środka plików PDF w poszukiwaniu meta tagów…
Racja, bo X-Robots-Tag to nagłówek odpowiedzi protokołu HTTP, co można zobaczyć np. w zakładce Sieć (Network) narzędzi deweloperskich:
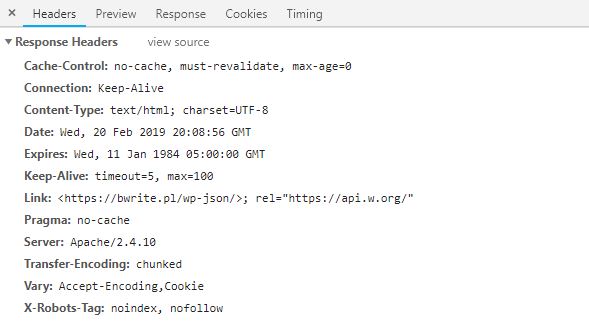
Jeśli chcesz zablokować indeksację plików w konkretnym katalogu z poziomu głównego katalogu domeny (normalnie należy dodać taki plik w konkretnym katalogu), należy posłużyć się regułami które znajdziesz w przykładach.
Noindex adresu URL
Dla dowolnego adresu URL również możesz dodać nagłówek X-Robots-Tag. Można to osiągnąć przez dodanie prostego zestawu reguł, opierających swoje działanie na trzech krokach:
- Sprawdzeniu adresu,
- Ustawieniu zmiennej środowiskowej,
- Ustawieniu nagłówka HTTP
I tak dla adresów zawierających w sobie słowo „test”, zostanie ustawiony wspomniany wcześniej nagłówek, tj. „noindex, nofollow”:
RewriteEngine On
RewriteRule test - [E=NOINDEX_HEADER:1]
Header Set X-Robots-Tag "noindex, nofollow" ENV=REDIRECT_NOINDEX_HEADERSpróbuj zmienić „REDIRECT_NOINDEX_HEADER” na „NOINDEX_HEADER” jeśli te reguły nie działają (wytłumaczenie poniżej)
Potrzebujemy dwóch linijek aby dodać interesujący nas nagłówek. Można też zauważyć że nazwa naszej zmiennej środowiskowej zmieniła się z NOINDEX_HEADER na REDIRECT_NOINDEX_HEADER. Zmiana ta spowodowana jest faktem działania tego kodu w środowisku WordPressa, gdzie zaraz po nim wykonane jest przekierowanie „wszystkiego” na plik index.php. W ten sposób serwer Apache oznacza zmienne, które istnieją już po przekierowaniu – dodawany jest prefiks „REDIRECT_„. Dlatego jeśli zastosujemy tę regułę np. dla katalogów, plików lub w innym środowisku, należy pamiętać o użyciu nazwy zmiennej bez prefiksu.
Więcej przykładów znajdziesz kilka akapitów niżej.
Meta tag a nagłówek HTTP
Nagłówek X-Robots-Tag jest traktowany przez wyszukiwarkę Google na równi ze znacznikiem metatag robots znajdującym się w sekcji <head> w kodzie źródłowym strony.
Uwaga! Jeśli jednocześnie będziemy mieli ustawiony metatag robots oraz nagłówek X-Robots-Tag na różne wartości, np.
<meta name="robots" content="index">Header Set X-Robots-Tag "noindex"to pod uwagę zostanie wzięta wartość najbardziej restrykcyjna, czyli „noindex”, więc Google nie zindeksuje danego zasobu. Dodatkowo możemy oczekiwać że zostanie to zgłoszone nam jako błąd w Google Search Console. Oczywiście inne wyszukiwarki, np. Bing mogą mieć inne ustawienia.
Przykłady
Poniżej znajdziesz kilka gotowych przykładów ( use cases ) gotowych do użycia w popularnych przypadkach:
Filtr w sklepie
Powiedzmy że w sklepie mamy taki link:
example.com/pl/c/courses/12/1/default/1/f_producer_3/
Część pogrubiona to fragment, który przenosi wartości filtra wybranego przez Użytkownika, w tym przypadku po producencie. Zależy nam aby taki link nie był indeksowany. Ponieważ chcemy zrobić to dla wszystkich producentów, przyjmiemy że ich oznaką jest fragment „f_producer_” (po którym następuje ID producenta w systemie, w tym przypadku „3”). Możemy tego dokonać dodając poniższy kod do pliku .htaccess:
RewriteEngine On
RewriteRule f_producer_ - [E=NOINDEX_HEADER:1]
Header Set X-Robots-Tag "noindex, nofollow" ENV=REDIRECT_NOINDEX_HEADEROk, to zadziała dla prostego URL bez parametrów (query). Do sprawdzenia adresu z parametrami, np. takiego:
example.com/pl/c/courses/12?f_producer=3
posłużymy się poniższym kodem (zauważ że została użyta zmienna %{QUERY_STRING} aby zbadać zawartość parametrów):
# Przy pomocy %{QUERY_STRING} sprawdzamy fragment
# "f_producer=3"
# czyli parametry
RewriteEngine On
RewriteCond %{QUERY_STRING} f_producer=
RewriteRule .* - [E=NOINDEX_HEADER:1]
Header Set X-Robots-Tag "noindex, nofollow" ENV=REDIRECT_NOINDEX_HEADERPamiętaj sprawdzić, czy blokowany przez ciebie fragment nie jest elementem np. URL do strony o producencie!
Pliki w katalogu
Powiedzmy że mamy folder do którego wrzucamy wszystkie pliki PDF, np. z ofertami lub kartami produktów, co tworzy nam takie linki:
- example.com/upload/products/book-one.pdf
- example.com/upload/products/book-two.pdf
- …
Możemy umieścić w pliku .htaccess poniższe reguły by nałożyć na takie pliki noindex:
RewriteEngine On
RewriteRule ^\/upload\/products\/.*\.pdf$ - [E=NOINDEX_HEADER:1]
Header Set X-Robots-Tag "noindex, nofollow" ENV=REDIRECT_NOINDEX_HEADERW tym przykładzie użyliśmy pełnoprawnego wyrażenia regularnego, składającego się ze znaku początku ciągu „^”, znaku ucieczki „\” (backslash), wyrażenia akceptującego dowolną ilość dowolnych znaków „.*” oraz znak końca ciągu „$”. REGEX – polecam, przednia zabawa 😉
Problematyczne URL
Przykład nieco wyrwany z kontekstu, ale każdy kto próbował ogarnąć „autorskie” CMSy lub nawet te popularne, ale z gorszą obsługą adresów wewnętrznych, znajdzie kilka przykładów.
Przyjmijmy że mamy CMS który tworzy w treści niepotrzebne linki do modułów zarządzających treścią – ot, zwykłe niedopatrzenie programistów lub architektów. Np. coś takiego:
- example.com/component/download/file.pdf
- example.com/index.php?mod=component&download=file.pdf
Mamy niepotrzebne linki w kodzie, do tego podwójne – w wersji „prostych adresów” jak i adresu opartego na parametrach. Poniższą regułą możemy wyciąć oba przypadki:
# Przy pomocy %{THE_REQUEST} sprawdzamy żądanie wysłane do serwera
# "GET /index.php?mod=component&download=file.pdf HTTP/1.1"
RewriteEngine On
RewriteCond %{THE_REQUEST} component
# Zamień powyższy RewriteCond na poniższy, jeśli chcesz mieć mniejszy margines błędu
# RewriteCond %{THE_REQUEST} (mod=component|\/component\/)
RewriteRule .* - [E=NOINDEX_HEADER:1]
Header Set X-Robots-Tag "noindex, nofollow" ENV=NOINDEX_HEADER
Header Set X-Robots-Tag "noindex, nofollow" ENV=REDIRECT_NOINDEX_HEADERWygląda dość skomplikowanie, prawda? Podwójna linia „Header Set…” spowodowana jest faktem, że standardowa konfiguracja CMS lub sklepu przepisze prosty adres (nagłówek zyska prefiks „REDIRECT_”) a odpytanie konkretnego pliku nie spowoduje przepisania (brak prefiksu).
Błędy
Przy wprowadzaniu reguł do pliku .htaccess możemy natrafić na kilka błędów. Widocznych od razu lub dopiero w skutkach – uważaj
Zawsze sprawdzaj „zmienione” URL oraz krytyczne adresy systemu gdy dokonujesz zmian w pliku .htaccess, np. dodając przekierowania. Sprawdź formularze kontaktowe, stronę koszyka oraz ścieżki zakupowe.
Error 500
Na ten błąd natrafisz od razu po wysłaniu zmian na serwer. Może oznaczać głównie błędy składni lub brak modułów Apache:
- literówka w składni reguł,
- błąd w składni, powstały np. przy wklejaniu fragmentu URL,
- niepotrzebna spacja, np. przeklejona wraz z regułami,
- brak aktywnego modułu mod_headers w serwerze Apache (zainstaluj i włącz moduł lub poproś o to swojego webmastera / usługodawcę). Np. na Debianie/Ubuntu możesz to zrobić poprzez uruchomienie dwóch komend w shellu (terminal otworzysz skrótem ALT+CTRL+T) – pierwsza aktywuje mod_headers, druga restartuje serwer Apache w celu wczytania nowej konfiguracji:
sudo a2enmod headers
sudo service apache2 restartReguły nie działają
To częsty przypadek, dlatego warto sprawdzić czy ustawiamy reguły na zmiennych, których zawartość w ogóle ma szanse zawierać to czego szukamy. Np. mamy adres „example.com/category?string=test” i próbujemy złapać go poniższą regułą:
RewriteCond %{REQUEST_URI} test
# dalsza część kodu...To normalne że nie zadziała, bo zmienna %{REQUEST_URI} nie zawiera fragmentu po znaku „?”, czyli parametrów. Powinniśmy użyć %{QUERY_STRING}. Dlaczego? Zobacz najczęściej używane zmienne mod_rewrite w Apache, które przydadzą Ci się w sprawdzaniu adresów. Jeśli chcesz sprawdzić co zawierają te zmienne, zerknij na artykuł o debugowaniu w .htaccessie.
Reguły działają na inne adresy / pliki
Sprawdź, czy wyrażenie którego szukasz nie jest zbyt ogólne. Użycie np. „produkt” pomoże wyindeksować filtry ale również wyindeksuje produkty. Spróbuj zmienić wzorzec, np.:
- rozszerzając go o znaki które mu towarzyszą (np. podkreślnik lub myślnik),
- dodając znaki początku lub końca ciągu w wyrażeniach regularnych (^ / $),
- budując bardziej rozbudowane wyrażenie regularne (REGEX),
- używając innej zmiennej (REQUEST_URI, QUERY_STRING, THE_REQUEST).
Reguły nadal nie działają lub działają zawsze
Może zdarzyć się że dodane ustawienia nadal nie działają (choć debugowanie wskazuje dobry URL) lub wręcz odwrotnie – działają na dowolny adres, choć dodaliśmy dyrektywę <Files>, <FilesMatch> lub odpowiedni RewriteCond aby ograniczyć nasze reguły do wąskiego zakresu interesujących nas URL.
Po pierwsze, nie znamy pełnej konfiguracji serwera (jeśli mamy dostęp tylko do .htaccess przez FTP). Wtedy warto dopytać osób „od serwera” dlaczego nasze reguły nie zachowują się tak jak tego oczekujemy. Czyli ostatnią deską ratunku, zwykle bardzo skuteczną, mogą być admini w naszej firmie lub dział pomocy u hostingodawcy.
Po drugie, z pozoru normalnie działający plik .htaccess nie musi być wcale używany przez serwer Apache. Jest wiele rozwiązań serwerowych, np. LiteSpeed lub IdeaWebServer, które niezależnie od tego co mają „pod spodem”, są kompatybilne z zamysłem przekazywania ustawień za pomocą pliku .htaccess. To oznacza że czytają taki plik i lepiej lub gorzej parsują jego ustawienia do swojego formatu, co jest świetne bo możemy stosować znane nam reguły lub instalować znane nam skrypty (co np. przy nginx by nie przeszło). Jeśli chodzi o popularne (i proste) reguły, można nie zauważyć różnicy. Czasem jednak możemy natrafić na omijanie przez te programy niektórych dyrektyw lub niepełne albo nieprawidłowe parsowanie – czyli na błędy. Takie błędy mogą powodować np. pomijanie deklaracji dyrektyw ale czytanie ich zawartości (czyli reguły zaczynają działać na dowolny URL). Np. wspomniany IdeaWebSerwer nie wspiera <FilesMatch> i wymaga użycia w to miejsce dyrektywy <Files> – dlatego najlepiej zrobić wywiad na czym właściwie pracujemy a następnie zastosować poprawki zawarte w dokumentacji tych serwerów, aby uniknąć „nadal niedziałających” reguł.