Prosta instrukcja krok po kroku jak używać systemu kontroli wersji GIT przy codziennej pracy. Dowiesz się jak zainstalować i używać GITa w terminalu, przy pracy lokalnej lub ze zdalnym repozytorium takim jak np. popularny GitHub.
Po co ten GIT
GIT to narzędzie które pomaga rozwijać oraz utrzymać projekty. Dostarcza jednemu lub całym zespołom developerów systemu wersjonowania plików. Bez tego praca na kodzie przez wielu ludzi (na wielu wersjach kodu) byłaby katorgą.
Przykład z życia. Przyjmijmy że w pracy zajmujemy się wprowadzaniem poprawek do stron Klientów. Robimy to w trybie mało bezpiecznym ale jakże często używanym – „na żywca” wprowadzamy zmiany na stronie bo nie istnieją osobne wersje dev/prod. Czyli zgrywamy kopię plików (backup), pracujemy na tych plikach a zmienione wersje wysyłamy na serwer. Co jeśli przyjdzie nam jednak cofać nasze zmiany? Musimy szukać oryginalnych plików w backupach. A czasem to któraś poprawka z kolei. Mamy backup po każdej poprawce? No właśnie 😉 Wystarczy zainicjować repozytorium i zrobić zapis po każdej poprawce. To bardzo szybki i wygodny proces. Potem już tylko jedna komenda i cofamy się do której wersji chcemy!
Kolejnym przykładem jest praca nad projektem (np. systemem CRM) w zespole. Czasy pracy gdzie każdy ma swoje konto na FTP i wrzuca swoje moduły, które potem są podgrywane przez adminów na serwer produkcyjny… mam nadzieję że się skończyły. Dzięki systemowi kontroli wersji GIT każdy programista może uzupełniać repozytorium o swoją porcję kodu, od razu widząc czy nie zmienił czegoś w tym samym pliku co inny programista. Na taką sytuację może odpowiednio zareagować dostosowując swój kod, ponieważ widzi kod i zmiany wszystkich współpracowników. W razie potrzeby może cofać zmiany z łatwością, bo istnieje pełna historia ich wprowadzania. Gdy zespół uzna że dany kod jest stabilny, można scalić go do głównej gałęzi gdzie już w bardzo prosty sposób może trafić na odpowiedni serwer, np. testowy.
GIT jako narzędzie w konsoli, o którym jest niniejszy poradnik, w przejrzysty i szybki sposób pozwala programiście komponować kod, zapisywać go i wysyłać na serwer. Po drugiej stronie, na serwerze, może czekać dodatkowo „nakładka” na ten system, w formie GitHuba, GitLaba czy podobnego rozwiązania. Pozwala to na webowy sposób poruszania się i interakcji z kodem, co bardzo ułatwia np. przeprowadzanie rewizji kodu czy zarządzanie projektem w całości.
Instalacja GIT
Instalacja może się różnić zależnie od systemu. Ten poradnik jest skierowany do użytkowników systemów linuxowych ze względu na przykłady w konsoli ale również na Windows można bez problemu zainstalować GITa (odsyłam do instrukcji w Internecie). Można tam również używać komend jak na Linuksie jeśli użyjemy WSL.
Na Debian/Ubuntu wystarczy jedna komenda w terminalu (którego możemy otworzyć skrótem Ctrl + Alt + T):
sudo apt-get install gitInstalacja sama w sobie nie wymaga dodatkowej konfiguracji ale musimy powiedzieć GITowi coś o nas żeby wiedział jak podpisywać nasze zmiany 😉 Ustawmy zatem wymagany email oraz nazwę:
git config --global user.email "[email protected]"
git config --global user.name "Imię Nazwisko"Super! Teraz gdy zapiszemy jakieś zmiany zobaczymy swoje imię, nazwisko oraz adres email jako autora:

Tak ustawiliśmy nazwę i email globalnie, czyli dla dowolnego repozytorium które będziemy używać na naszym koncie użytkownika. Możemy również użyć zamiast przełącznika --global wartości --system aby zmienić ustawienia dla wszystkich kont w systemie. Najczęściej jednak możemy być zainteresowani przełącznikiem --local, dzięki któremu zmienimy ustawienia dla repo w którym akurat się znajdujemy. Każde repo możemy przecież inaczej „podpisywać” (praca/open source/prywatny projekt, etc.).
Lokalne repozytorium GIT
Lokalne repozytorium pozwala nam na o wiele wygodniejszą i bezpieczniejszą pracę z plikami projektu. Co prawda jeszcze nigdzie nie wysyłamy naszych zmian, więc bezpieczeństwo ustępuje wygodzie – ale to pierwszy krok do lepszej pracy z kodem. I czasem wystarczający, jeśli i tak robimy backup w „tradycyjny” sposób.
Będąc w terminalu przechodzimy do katalogu w którym chcemy przechowywać pliki naszego projektu, lub gdzie już mamy jakieś pliki (np. zgrane z FTP) które chcemy wersjonować. Następnie uruchamiany komendę utworzenia (zainicjowania) nowego repozytorium:
git initNiezależnie od tego czy w katalogu były już jakieś pliki czy był pusty, po uruchomieniu tej komendy GIT utworzy w nim ukryty podkatalog .git (jeśli już istnieje – zostaniemy o tym poinformowani i GIT zakończy pracę). W tym podkatalogu GIT przechowuje wszystkie informacje o repozytorium, takie jak wersje danych czy ustawienia.
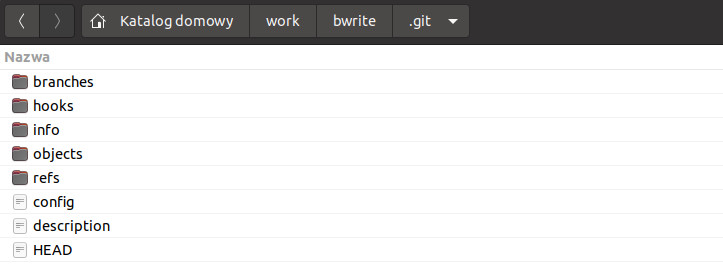
Dzięki temu GIT wie, że dany katalog stanowi repozytorium i porównuje to co jest w katalogu z tym co przechowuje w swoim podkatalogu.
W tym momencie mamy utworzone nowe repozytorium, które wykrywa zmiany w plikach, ale jeszcze nic nie zostało zapisane – powinniśmy dodać pliki do zapisania oraz ostatecznie je zapisać – to zwykle tylko dwie komendy. Przejdźmy zatem do śledzenia plików i składania zmian.
Dla uproszczenia, ten poradnik możemy „przejść” w jednym oknie konsoli, nie rozpraszając się innymi sprawami. Oczywiście możemy otworzyć nasz katalog z repo w swoim edytorze lub IDE, jak choćby w Visual Studio Code, i w ten sposób tworzyć oraz edytować pliki.
Śledzenie plików
Pierwszym krokiem przed zapisem jest oznaczenie plików jako śledzone przez GITa. Zobaczmy w ogóle na czym stoimy, uruchamiając odpowiednią komendę:
git statusNa razie dowiemy się tylko że jesteśmy na gałęzi master (pierwsza, domyślna gałąź), nic jeszcze nie zapisywaliśmy oraz nie mamy żadnych zmian do złożenia (ang. commit). Do gałęzi jeszcze wrócimy.

Teraz nie wychodząc z terminala utwórzmy dwa pliki poleceniem touch i ponownie odpalmy git status. Teraz zobaczymy dodatkowo informację, że istnieją pliki które nie są śledzone oraz podpowiedź jak je dodać do śledzenia:
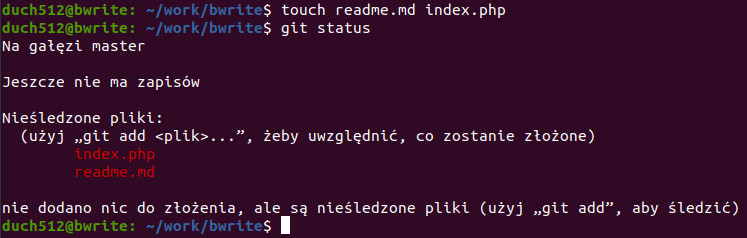
GIT proponuje nam, abyśmy uruchomili komendę „git add <plik>”. Dzięki temu możemy śledzić pojedyncze pliki, jeśli np. chcemy potem zapisać tylko część plików. Aby dodać oba te pliki, możemy wpisać taką komendę dwa razy:
git add index.php
git add readme.mdalbo wypisać je po spacji:
git add index.php readme.mdlub jeśli wiemy że chcemy dodać wszystkie pliki, wystarczy użyć znaku kropki:
git add .Wszystkie powyższe komendy będą miały ten sam wynik – dodamy oba nasze pliki do śledzenia. Zobaczmy co teraz nam powie „git status”:
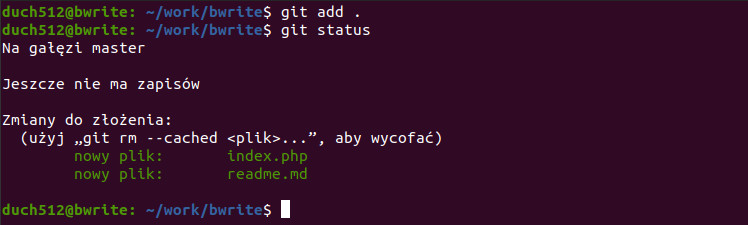
Jak widać, GIT już śledzi nasze pliki. Równocześnie proponuje nam, że możemy wycofać się ze śledzenia tych plików poprzez uruchomienie komendy git rm --cached <plik>. Gdybyśmy to zrobili, wrócimy do stanu sprzed uruchomienia git add, czyli plik zostałby oznaczony jako nieśledzony. Możemy również cofnąć śledzenie wszystkich plików przy pomocy komendy git reset.
Spróbujmy teraz zmodyfikować zawartość któregoś z nich – dodajmy trochę tekstu do pliku readme.md i ponownie odpalmy polecenie git status. Aby nie otwierać edytora, zrobię to z poziomu okna konsoli wykonując echo które podobnie jak w PHP wypisuje ciąg znaków. Następnie „operatorem tworzenia lub nadpisania zawartości” > kieruję ten ciąg znaków do pliku readme.md zamiast do konsoli:
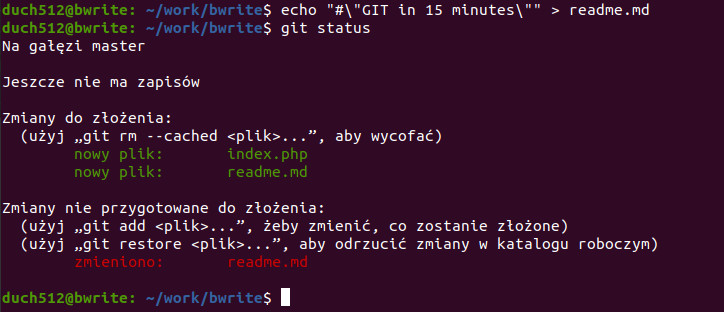
Dodaliśmy treść do wcześniej pustego pliku, a więc dokonaliśmy zmiany w śledzonym pliku. Dostajemy teraz informację, że istnieją dwa śledzone pliki a równocześnie jeden z nich zawiera zmiany nie przygotowane do złożenia. To oznacza, że GIT w momencie uruchomienia git add zapamiętał sobie stan plików podanych w tym poleceniu. Jeśli znów coś zmienimy w plikach, GIT zauważy, że ich zawartość zmieniła się względem tego co „oznaczyliśmy” przy okazji uruchomienia komendy śledzenia. To dobry moment aby trwale zapisać nasze zmiany.
Komendy GITa użyte do tej pory:
git init– utworzenie repozytorium w katalogugit status– sprawdzenie obecnego stanu repogit add– dodanie plików do śledzenia
Dodatkowe komendy do cofania git add:
git rm --cached <plik>– cofnięcie śledzenia konkretnego plikugit reset– cofnięcie śledzenia wszystkich plików
Zapisanie zmian
Pliki oznaczone do śledzenia (widoczne na zielono po uruchomieniu git add) możemy trwale zapisać jako commit (po polsku „złożone zmiany” 😉 ). Dzięki temu utworzymy swoisty punkt w historii repozytorium do którego będziemy mogli wracać w razie potrzeby. Żeby zobaczyć nasze zapisy, możemy uruchomić komendę git log. Oczywiście teraz nasze repozytorium nie ma żadnych zapisów. Dodajmy zatem pierwszy commit (pamiętajmy że mamy na stanie dwa „zielone” pliki i jeden „czerwony”).
Commit możemy dodać na dwa sposoby, po prostu uruchamiając odpowiednią komendę:
git commitCo uruchomi nam „interaktywny” tryb dodawania zapisu, tj. otworzy domyślny edytor (w moim przypadku nano) gdzie możemy dodać opis naszej zmiany a następnie korzystając z opcji zapisu w edytorze, zapisać commit.
Znacznie szybciej jest wykorzystać przełącznik -m (message) i dodać opis od razu w poleceniu:
git commit -m "Init a git15 repo!"Zanim zapiszemy naszego pierwszego commita, warto wiedzieć jak właściwie powinniśmy go opisać. Jest to niezwykle ważna rzecz, ta z kategorii „teraz wiem o co chodzi, ale jutro już mogę zapomnieć”. Dlatego dla Twojego i twoich współpracowników dobra, proponuję świetny artykuł jak pisać dobre commity.
Gdybyśmy w powyższym poleceniu git commit -m ... wcisnęli Enter przed postawieniem końcowego znaku cudzysłowu, polecenie zamiast wykonać się, przejdzie do kolejnej linii – przydatne jeśli chcemy oddzielić tytuł i dłuższy opis (zgodnie z artykułem o dobrych commitach) bez otwierania edytorka.
Uruchamiamy więc komendę git commit -m "Init a git15 repo!". Tym razem uruchomimy dodatkowo git log aby zobaczyć co mamy zapisane (czyli nasz obecny commit) oraz standardowo sprawdzimy stan naszego repo:
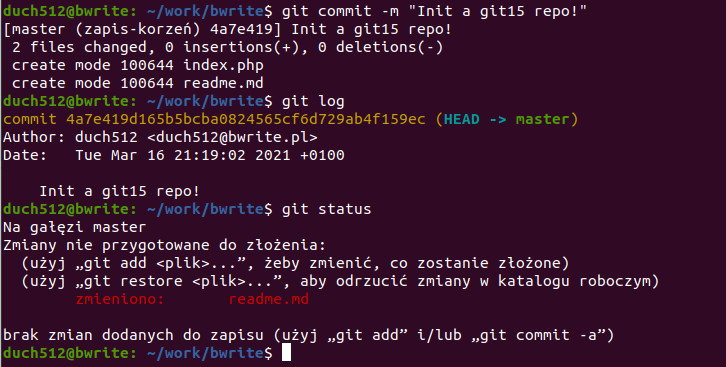
Po wykonaniu komendy złożenia zmian GIT informuje nas, że dokonał zapisu na gałęzi master która jest główną gałęzią (korzeniem naszego drzewa), jego skrócony unikalny identyfikator (hash) to 4a7e419 i posiada opis „Init a git15 repo!”. Następnie możemy się dowiedzieć, że 2 pliki zostały zmienione (nie istniały w repo, więc zmieniły się), 0 linii zostało dodanych/usuniętych (no cóż, pliki były puste). Na koniec mamy wylistowane pliki wraz z wykonanymi na nich operacjach.
Następnie uruchamiamy dziennik zmian (git log). Widzimy że jest w nim jeden commit, o identyfikatorze (hashu) 4a7e419... (w przeciwieństwie do zwrotki z commita widzimy jego pełną wartość). Mamy również informacje o autorze (które podawaliśmy podczas konfiguracji), datę złożenia zmian oraz opis.
W statusie widzimy że „zielone” pliki zniknęły (czyli zostały złożone – „zakomitowane”). Jak widać, „czerwony” plik czyli zmiany które dokonaliśmy już po git add . nie zostały złożone i dalej na nas czekają. To oznacza, że po każdych zmianach w plikach na których pracujemy GIT oczekuje od nas decyzji czy dodać ich obecny stan do śledzenia (przygotować do zakomitowania). Dlatego zawsze przez wykonaniem git commit warto sprawdzić w jakim stanie jest nasze repozytorium aby uniknąć częściowych zapisów 🙂
Gdy skończyliśmy pracę nad porcją kodu i chcemy ją zapisać do repozytorium, wykonujemy 3 kroki:
git status– aby sprawdzić na czym stoimy 😉git add <pliki lub wzorzec>– aby wskazać pliki do zapisugit commit -m "Opis zmian"– aby zapisać zmiany
Cofanie zmian
Dokonaliśmy już pierwszych zapisów i mamy jeden „czerwony” plik czekający na oznaczenie i zapisanie, readme.md. Co jeśli chcielibyśmy cofnąć zmiany w tym pliku ale akurat nie możemy zrobić tego „ręcznie” w edytorze (np. używając skrótu Ctrl + Z) oraz nie wiemy co tam było wcześniej, więc zmiana jego zawartości też nie wchodzi w grę?
Chowanie zmian „na chwilę”
Bardzo wygodnym i bezpiecznym sposobem cofania zmian jest użycie Schowka (ang. stash). Schowek to takie miejsce w gicie gdzie możemy wrzucać nie powiązane ze sobą wersje plików (w przeciwieństwie do commitowania na gałęzi). Bardzo przydatny gdy akurat nad czymś pracujemy i musimy na chwilę wrócić do „czystego” stanu aby np. coś poprawić lub zerknąć na oryginalne pliki. Jego użycie jest bardzo proste, wystarczy użyć komendy git stash:
git stash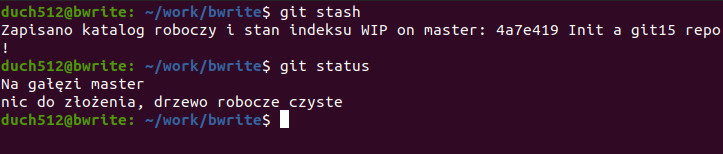
To spowoduje zapisanie wszystkich zmienionych plików do schowka. Jak widać w statusie, drzewo robocze jest czyste. Schowek zapisuje zmiany na zasadzie stosu, więc jeśli chcemy przywrócić ostatni zapis (a najczęściej właśnie to robimy), wystarczy uruchomić komendę:
git stash apply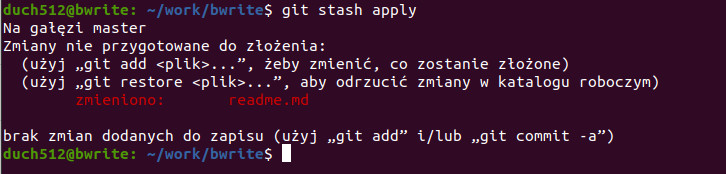
Teraz wróciliśmy do stanu z przed chwili. Oczywiście trudno w dłuższej perspektywie operować tylko używając ostatniego elementu, dlatego dla zmian o dłuższej żywotności warto dodać własny opis, podobnie jak w przypadku commita. Stwórzmy sobie jeszcze jeden plik wykonując touch robots.txt i wypróbujmy schowek ponownie, tym razem dodając przykładowy opis. Użyjemy do tego pod-komendy push z flagą -m (message).
git stash push -m "Fix #1 but #2 crashed"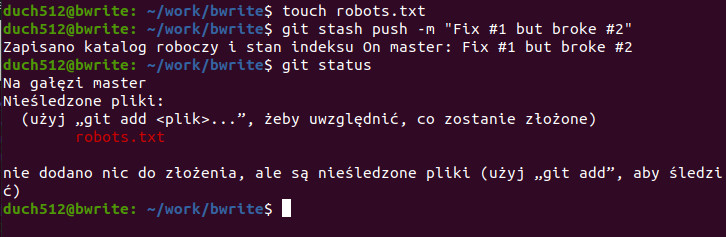
Tym razem drzewo robocze nie jest czyste – został nam nowo utworzony plik robots.txt. Tak, bo domyślnie git stash zapisuje tylko śledzone pliki (ogólnie GIT bierze pod uwagę tylko śledzone pliki). Cofnijmy się wykonując git stash apply, następnie dodajmy wszystkie pliki do śledzenia git add . i ponownie schowajmy zmiany:
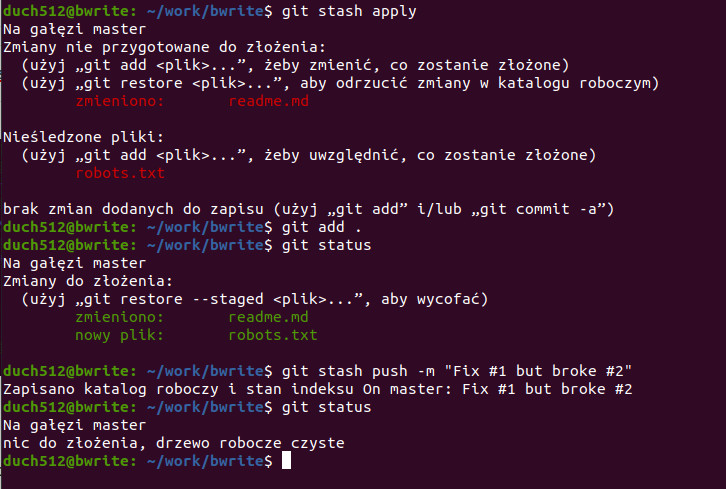
Świetnie, teraz mamy porządek 🙂 Zobaczmy zatem przy pomocy komendy git stash list co tam mamy w schowku:
git stash list
Teraz widzimy stos naszego schowka. Najpierw wrzuciliśmy do niego jakieś zmiany z gałęzi master opisane automatycznie przez GITa jako „WIP on master <skrót informacji o ostatnim commicie>” (WIP = work in progress) a następnie dwa razy dodaliśmy zmiany z opisem „Fix #1 but…” (bo sprzątaliśmy mały bałagan).
Jeśli chcemy przywrócić konkretny schowek z listy, można to zrobić używając jego identyfikatora „stash@{<int>}” w komendzie git stash apply. Wróćmy się do naszego pierwszego zapisu:
git stash apply stash@{2}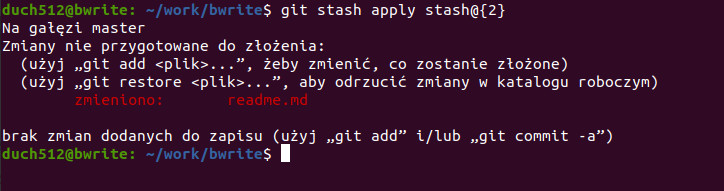
W ten sposób wczytaliśmy stan plików, gdzie jeszcze nie było naszego nowego pliku robots.txt. Nie jest to nasz najnowszy stan plików i moglibyśmy znów go schować aby wczytać nowszą wersję, ale czy warto robić kolejny schowek? Przejdźmy zatem do kolejnego punktu, w którym zobaczymy jak trwale porzucać wprowadzone zmiany w plikach.
Aby cofnąć wprowadzone zmiany z możliwością wrócenia do nich, używamy Schowka:
git stash– schowanie wszystkich śledzonych plikówgit stash list– wylistowanie stosu schowkagit stash apply– przywrócenie ostatnio zachowanych plikówgit stash apply stash@{<int>}– przywrócenie konkretnego schowka
Porzucanie zmian w plikach
Jeśli tylko coś sprawdzamy na szybko (np. debugujemy) albo jesteśmy pewni że wprowadzone zmiany nie będą nam potrzebne, możemy trwale porzuć nasze zmiany. Można to zrobić na dwa sposoby. Używając komendy git reset z opcją --hard:
git reset --hardTo jak widać po nazwie, opcja tylko dla prawdziwych twardzieli 😉 Bardziej precyzyjnie będzie móc porzucić zmiany dla konkretnego pliku a i tak najczęściej modyfikujemy na raz niewiele plików. Możemy to zrobić używając bardzo przydatnej komendy git checkout -- <plik>. O samej komendzie dowiemy się więcej w punkcie o pracy na gałęziach.

Porzućmy zatem zmiany w pliku readme.md który wczytaliśmy z nie-najnowszego schowka:
git checkout -- readme.md
Jak widać zmiany na pliku readme.md wyparowały w nicość i nasze drzewo robocze jest czyste. Przejdźmy do kolejnego punktu i zobaczmy jak cofać zmiany które już zapisaliśmy do gałęzi poleceniem git commit.
Cofanie commitów
Czasem chcemy cofnąć cały commit, bo np. wykonaliśmy go przez pomyłkę, jest w nim błąd lub z dowolnie innego powodu nie jesteśmy z niego zadowoleni. Bezpieczną metodą jest użycie komendy odwracania zmian zamiast usuwania. Komenda ta wykona dokładnie taką pracę, jakbyśmy ręcznie usunęli zmiany które wprowadził dany commit i ponownie go zapisali. Git utworzy commit ze zmianami odwrotnymi do wskazanego commita i zapisze go.
Dodajmy kolejny plik, bad-file.php i zakomitujmy go. Ponieważ to zły plik, chcemy teraz cofnąć nasz ostatni commit przy pomocy komendy git revert <hash>. Aby nie musieć sprawdzać jaki hash ma nasz ostatni commit, możemy posłużyć się wskaźnikiem HEAD. Ten wskaźnik można rozumieć jako to „na co właśnie patrzymy”. Zawsze patrzymy na jakąś gałąź (teraz master) oraz, jeśli już mamy, jakiś commit. Gdzie my, tam HEAD 😉
git revert HEAD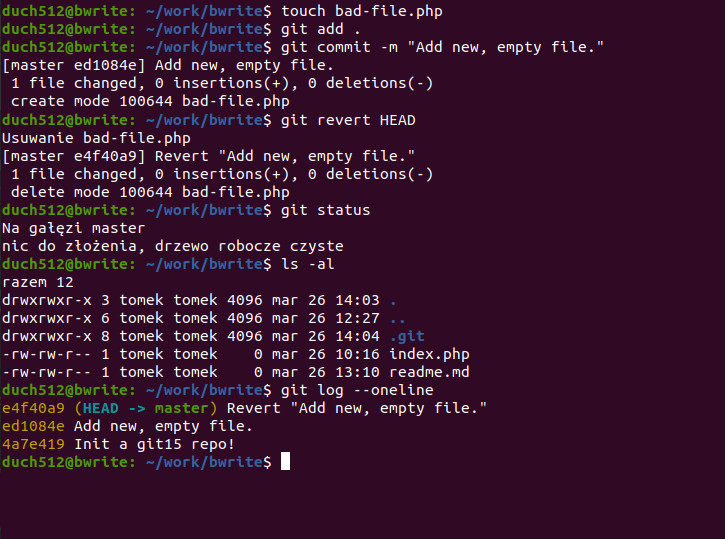
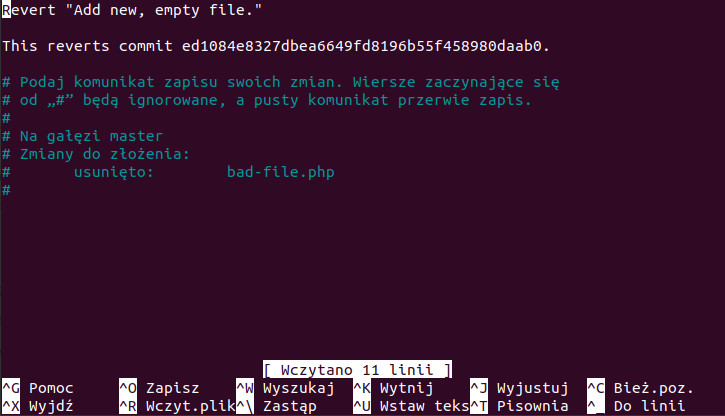
Po utworzeniu pliku (zmian), dodaniu do śledzenia i zapisaniu naszła nas ochota na wycofanie ostatniego commita. Używając komendy git revert wskazaliśmy że chcemy cofnąć zmiany względem ostatniego commita przy pomocy HEAD zamiast sprawdzać hash w git log (który miał w tym przypadku wartość ed1084e). Po wykonaniu komendy odwracania, otworzony zostaje edytor (w moim przypadku nano) gdzie możemy opisać dlaczego cofamy zmiany lub po prostu przejść dalej wychodząc z edytora (w nano to widoczny skrót Ctrl + X). Następnie sprawdzamy status – drzewo jest czyste. Listujemy pliki w katalogu – nie ma już bad-file.php. Sprawdzamy jak sytuacja wygląda w historii, uruchamiając git log, tym razem z opcją --oneline która skraca wpisy do hashu i tytułu (pierwszej linii opisu). Widzimy, że jesteśmy na gałęzi master (a HEAD na nią wskazuje) i że pojawił się nowy commit, gdzie GIT automatycznie dopisał do tytułu „Revert…”.
Zmiany zostały bezpiecznie wycofane z gałęzi. Jeśli chcemy, nadal możemy do nich wrócić bo nie zniszczyliśmy żadnego punktu w historii gita.
Co jeśli, szczególnie pracując lokalnie, chcemy trwale usunąć zapisane zmiany? O tym w kolejnym punkcie.
Usuwanie commitów
Trwałe usuwanie commitów ma swoje uzasadnienie choćby przez fakt, że np. opis który dodaliśmy jest „nieładny”, ot, literówka bądź nie to słowo. Trzeba jednak pamiętać że zaburzamy w ten sposób utworzoną historię gita i jeśli naszą pracę wysyłamy potem na zdalny serwer, gdzie ktoś inny też pracuje na repo, może to stwarzać problemy.
Usuńmy zatem commit z informacją o odwracaniu zmian, czyli zresetujmy historię do commita dodanego przed nim przy pomocy komendy git reset <hash>. To ta sama komenda której użyliśmy do cofnięcia komendy git add ale tym razem wskazujemy konkretny commit (domyślnie to nasz HEAD).
git reset ed1084e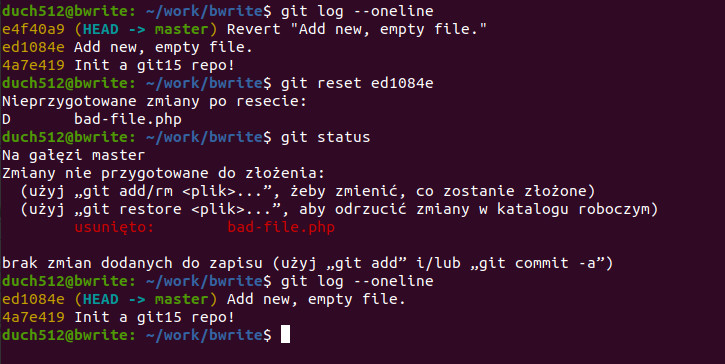
Sprawdzamy naszą historię i pozyskujemy hash commitu do którego chcemy się cofnąć, porzucając WSZYSTKO po drodze (nie możemy po prostu „wyjąć” jednego commita z historii). Uruchamiamy git reset <hash> i otrzymujemy informację że posiadamy nieprzygotowane zmiany. Dzieje się tak, ponieważ domyślnie git reset uruchamia się z opcją --mixed która przenosi resetowane zmiany (ze wskazanego commita) do naszego drzewa roboczego. Widzimy więc, że wrócił plik bad-file.php który jest oznaczony jako usunięty (bo wtedy usunęliśmy go revertem). Punkt w historii został usunięty, co widać w logu.
Aby zobaczyć jak zadziała komenda git reset --hard <hash>, pójdźmy za radą gita i przywróćmy plik (cofnijmy jego status „usunięto”). Następnie zakomitujmy go, aby mieć co resetować:
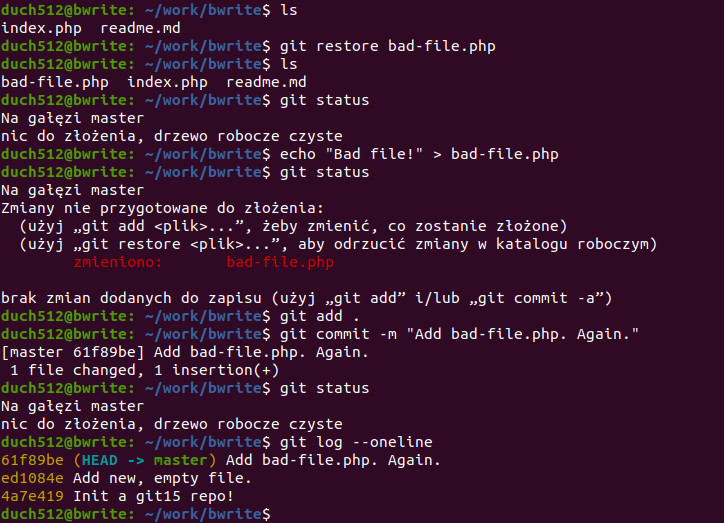
Skoro znów mamy co resetować, wypróbujmy trwałe resetowanie:
git reset --hard ed1084e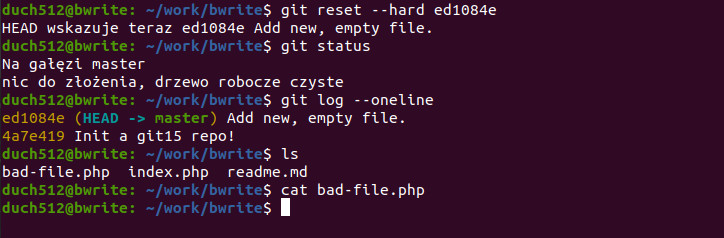
Resetujemy commit ed1084e, tym razem z opcją --hard. Drzewo robocze jest czyste a z historii zniknął nasz poprzedni commit. Ponieważ wcześniej przywróciliśmy „usunięty” plik, mamy go z powrotem na liście ale jak widać jest pusty – nie ma zmian które dodaliśmy we wcześniejszym kroku.
Aby trwale usunąć wprowadzone zmiany w drzewie roboczym:
git checkout -- <plik>– usuwanie zmian z konkretnego plikugit reset --hard– usuwanie zmian z wszystkich plików
Aby cofnąć lub trwale usunąć commity:
git revert <hash>– odwracanie (cofanie) zmian z wskazanego commitugit reset <hash>– usuwanie commitów aż do wskazanego commitu, z pokazaniem zmian po nimgit reset --hard <hash>– usuwanie aż do wskazanego commitu
Praca na gałęziach
Do tej pory operowaliśmy na gałęzi master, ale jak nazwa wskazuje, to powinna być główna gałąź naszego repo czyli zawierająca kod w jego najlepszej jakości (produkcyjny). Zobaczmy zatem co oferuje nam GIT.
Tworzymy nową gałąź (branch)
Mógłbym teraz zaproponować użycie komendy git branch <nazwa_gałęzi> która jasno wskazuje do czego służy, ale o wiele wygodniejsze i intuicyjne jest utworzenie gałęzi komendą git checkout która służy do przemieszczania się np. do innej gałęzi czy commita (a gdzie my, tam HEAD ;)) i jest dość wszechstronna (np. porzucaliśmy przy jej pomocy zmiany).
Obecnie znajdujemy się na gałęzi master, na której mamy już jakiś dorobek. Oczywistym jest, że chcemy kontynuować jego rozwijanie, a wiec chcemy bazować na tym kodzie. Wykonajmy polecenie git branch <nazwa_gałęzi> tworząc nową gałąź:
git branch bad-branchNastępnie utwórzmy kolejną gałąź poleceniem git checkout (przełączanie na inną gałąź) razem z flagą -b (jak ang. branch) i podając nazwę nowej gałęzi:
git checkout -b developNastępnie wylistujmy nasze gałęzie, używając wreszcie git branch:
git branch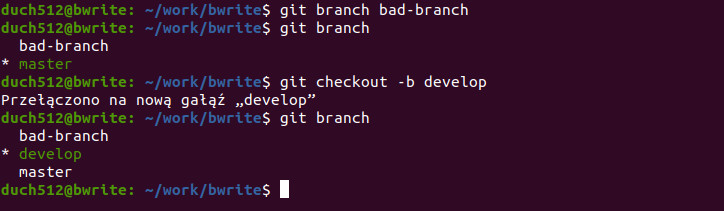
Utworzyliśmy tym sposobem dwie gałęzie, bad-branch oraz develop. Jak widać różnica pomiędzy tymi dwoma sposobami jest taka, że ten drugi automatycznie przeniósł nas na nowo utworzoną gałąź (na liście aktywna gałąź jest poprzedzona gwiazdką i ma zielony kolor). Tak się składa że to bardzo pożądane, więc skoro i tak często używamy git checkout, warto używać takiego skrótu. Dodatkowo checkout przeniesie ze sobą śledzone pliki. 3 w 1 😉
Przełączamy się pomiędzy gałęziami
W pracy często przełączamy się pomiędzy gałęziami i tu wystarczy użyć znanego nam już polecenia git checkout <nazwa_gałęzi> podając po nim nazwę interesującej nas gałęzi. Ponieważ jesteśmy aktualnie na gałęzi develop, wróćmy na gałąź bad-branch:
git checkout bad-branchNastępnie namieszajmy trochę, usuwając plik index.php i zapisując zmiany. Potem przełączmy się z powrotem na developa:
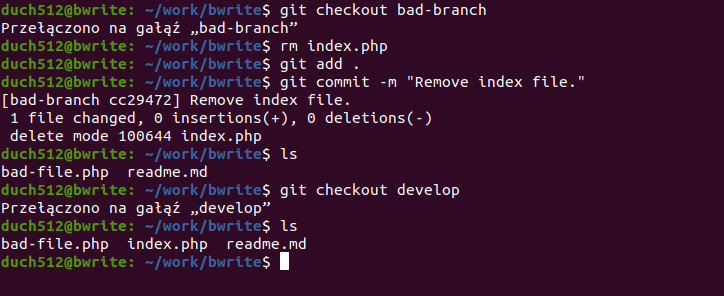
Jak widać jeśli chcemy pracować nad nową funkcjonalnością lub po prostu coś potestować, wystarczy że przełączymy się na nową gałąź i wszystko zostanie właśnie tam. Należy jednak pamiętać o naszej gałęzi roboczej. Nie śledzone pliki „przechodzą” pomiędzy gałęziami gdy się przełączamy. Śledzone pliki również przechodzą, ale zostaniemy o tym poinformowani podczas lub po przełączeniu (jeśli nie było konflików).
Przełączamy się pomiędzy commitami
Podobnie jak między gałęziami, możemy „wracać” do wcześniejszych commitów, np. aby podejrzeć zmiany lub po prostu na tej podstawie zrobić nową gałąź. Przełączmy się zatem na konkretny commit komendą git checkout <hash>:
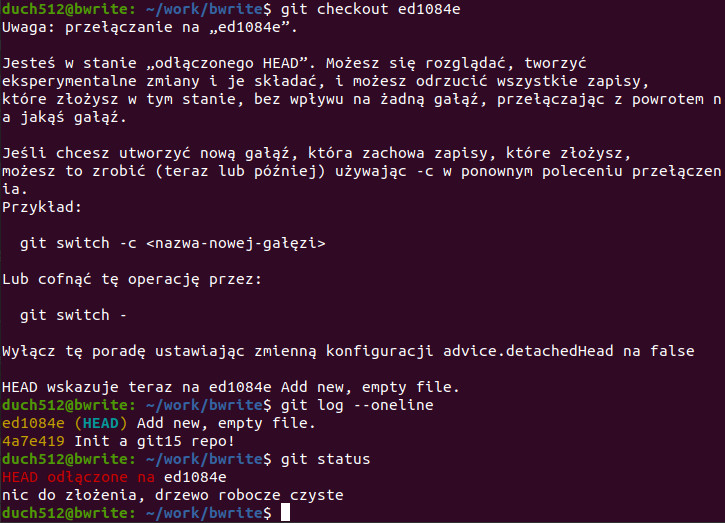
Jak widać, GIT bardzo wylewnie informuje nas, że nie jesteśmy już na żadnej gałęzi (odłączyliśmy się naszym wskaźnikiem HEAD w jakieś inne miejsce). git log pokazuje jako najnowszy commit ten na który się przełączyliśmy (nie widzimy nowszych). W statusie widać że patrzymy na ed1084e ale nie jest to żadna konkretna gałąź.
Co teraz? Możemy oczywiście wykonać komendę git checkout -b <nazwa_nowej_gałęzi> żeby na bazie dotychczasowego logu zrobić nową gałąź. Możemy też zobaczyć np. w IDE jak wygląda kod w tym miejscu (pliki zostały coænięte do tego stanu).
Aby wyjść ze stanu „odłączonego HEAD” (ang. detached HEAD) wystarczy przełączyć się np. na jakąś gałąź poleceniem: git checkout develop. I tyle, znów jesteśmy bezpieczni 😉
Usuwamy gałęzie
Do usuwania gałęzi dochodzi raczej rzadko i robimy to albo żeby posprzątać bo mamy za dużo gałęzi albo… nie, innego powodu nie widzę. Od nadmiaru głowa nie boli, a kto wie kiedy kod z danej gałęzi może się przydać 😉
Możemy usunąć gałąź komendą git branch z przełącznikiem -d (delete) i podając nazwę gałęzi. Jesteśmy na developie więc prawdopodobnie możemy usunąć nieaktywną gałąź bad-branch:
git branch -d bad-branch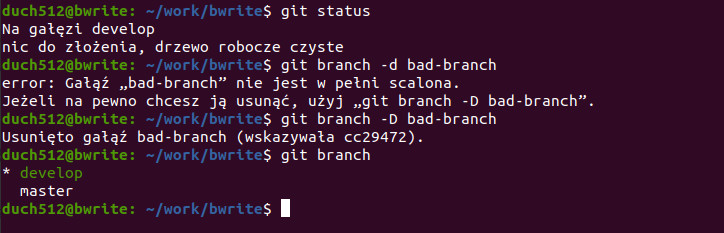
Po uruchomieniu komendy usuwania GIT informuje nas że gałąź ta nie jest w pełni scalona i powinniśmy użyć innej opcji (co robimy). Zadziało się tak dlatego, że przy usuwaniu GIT sprawdza czy dana gałąź jest aktualna względem HEAD (czyli tam gdzie teraz jesteśmy – gałąź develop). Zamiana małej litery „d” na wielką „D” spowodowała to samo co w wielu innych poleceniach Linuxa – został dodany tryb „force”.
Łączymy gałęzie
Kwintesencją GITa jest scalanie, czyli merge gałęzi ze sobą. Pozwala to na połączenie pracy wielu ludzi w jedną spójną całość.
Utwórzmy zatem nową gałąź „rozwojową”, dodajmy co nieco do pliku index.php, zapiszmy zmiany i scalmy gałąź develop do gałęzi master przy pomocy polecenia git merge <nazwa_gałęzi>.
git merge develop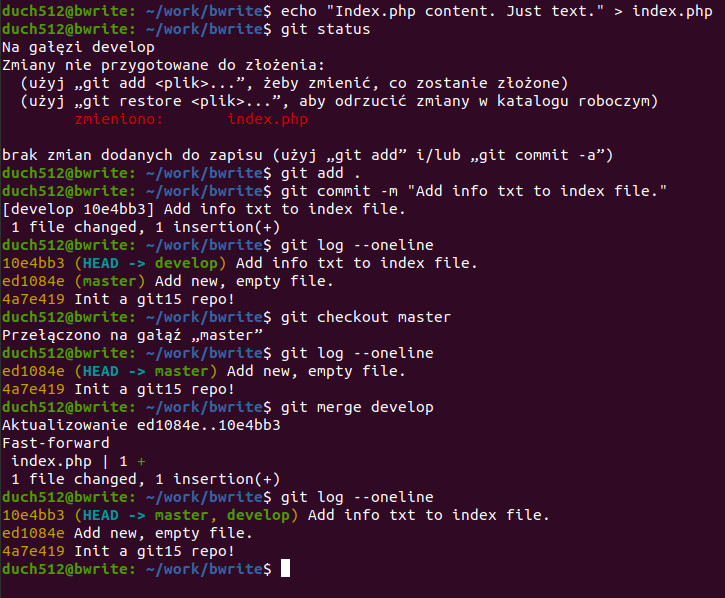
Dodaliśmy trochę tekstu do pliku index.php. Zapisujemy zmiany znaną nam procedurą. Widzimy że pojawił się nowy punkt w logu – HEAD wskazuje na develop, ostatnia aktualny commit z gałęzią master jest poniżej. Przełączamy się na gałąź master gdzie widzimy że nie mamy najnowszego commita więc wykonujemy polecenie git merge <nazwa_gałęzi> w celu scalenia zmian ze wskazanej gałęzi. Otrzymujemy informację że trwa aktualizowanie z <hash> do <hash>, następnie widzimy że użyty został tryb „szybkiego przewijania”. Ponieważ nasze commity następowały po sobie, GIT nie musiał scalać niczego wewnątrz plików więc tylko „przewinął” w przód. Potem widzimy listę plików w których nastąpiły zmiany, numeryczną wartość zmodyfikowanych linii kodu oraz graficzną reprezentację ilości dodanych/usuniętych linii. Jeden plus/minus to jedna linia a jeśli ilość znaków przekraczałaby długość linii w konsoli, plusy/minusy wskażą tylko na proporcję dodanego/usuniętego kodu.
Unikanie konfliktów
Droga scalania czasem najeżona jest konfliktami (GIT nie może ustalić która wersja jest najnowsza). Można jednak zminimalizować ten problem prawie do zera. Gdy stworzymy nową gałąź np. na podstawie gałęzi master i popracujemy nad nią jakiś czas, praktycznie pewnym jest (szczególnie przy pracy ze zdalnym repo, czyli innymi ludźmi) że gałąź master będzie posiadała zmiany których nie mamy na swojej gałęzi. Wykonanie potem git merge do mastera przyniosłoby nam szereg konfliktów w plikach, które musielibyśmy poprawić ręcznie.
Dobrą praktyką jest okresowe (np. rano przy rozpoczęciu pracy) mergowanie zawartości gałęzi „bazowej” do naszej „roboczej” gałęzi. To pozwoli zorientować się nam w powstających zmianach i będziemy mogli rozwiązać ewentualne konflikty w małych dawkach, od ręki.
Kolejną jeszcze lepszą praktyką jest zrobienie tego samego co powyżej, ale bezpośrednio przed próbą merge (lokalnie) lub wysłaniem zmian na serwer (praca ze zdalnym repo).
Praca w takim trybie jest wysoce wskazana dla swojego i współpracowników dobra 😉 Dzięki temu rozwiązujemy konflikty na bieżąco i merge przechodzą bezproblemowo. Jesteśmy też w stanie szybciej dostarczyć zmiany jeśli dojdzie do krytycznej sytuacji w projekcie i potrzebujemy czegoś „na już”.
Aby utworzyć/usunąć gałąź:
git branch <nazwa– stworzenie nowego brancha_gałęzi>git checkout -b <nazwa– stworzenie brancha i przełączenie się na niego_gałęzi>git branch -d <nazwa– usunięcie brancha (będąc na innej gałęzi)_gałęzi>
Aby przełączyć się na inną gałąź lub commit:
git checkout <nazwa/hash>– przełączenie na inną gałąź/commit (a gdzie my, tam HEAD 😉 )
Aby scalić (zmergować) gałęzie:
git merge <nazwa– scalanie brancha <nazwa_gałęzi>_gałęzi> do gałęzi na której jesteśmy
Zdalne repozytorium GIT
Gdy już wiemy jak pracować z lokalnym repozytorium – dodawać, cofać i składać zmiany, nadszedł czas na podłączenie się do jakiegoś fajnego serwera i wysyłanie tam naszej pracy. To pozwoli na większe bezpieczeństwo kodu i oczywiście na dzielenie się nim lub wspólną pracę. Zdalne repozytorium (ang. remote) może znajdować się np. na firmowym serwerze czy też u odpowiedniego usługodawcy. Możemy logować się do niego za pomocą loginu/hasła lub (bezpieczniej i wygodniej) klucza SSH. Następnie możemy pobierać oraz wysyłać tam zmiany z naszego lokalnego repozytorium.
Tworzymy zdalne repozytorium
Na początek weźmy na cel utworzenie nowego repozytorium na GitHubie, co jest bardzo proste – wszystko „wyklikujemy” w przeglądarce. Możemy tam tworzyć publiczne ale także prywatne repozytoria, więc to świetne miejsce na udostępnianie swojego dorobku czy też trzymanie swoich projektów. Takie repozytorium nie różni się od tego które spotkasz w pracy, więc jest to dobry wybór.
Po utworzeniu konta proponuję w ustawieniach konta dodać swój klucz SSH. Dzięki temu nie będziemy musieli wciąż wpisywać loginu/hasła i praca będzie o wiele przyjemniejsza i bezpieczniejsza.
Gdy już wszystko mamy ustawione, korzystamy z opcji „New repository”, następnie nadajemy mu nazwę:


Po nadaniu nazwy możemy w zasadzie kliknąć „Create repository” lub jeszcze np. zmienić dostępność z (domyślnie) publicznej na prywatną. Zostaniemy przeniesieni do strony głównej naszego repozytorium, gdzie prezentowany jest jego adres:
[email protected]:duch512/git15.gitDodajemy zdalny serwer do lokalnego repo
Mając jego adres, możemy dodać zdalny serwer do repo na którym do teraz pracowaliśmy:
git remote add origin [email protected]:duch512/git15.git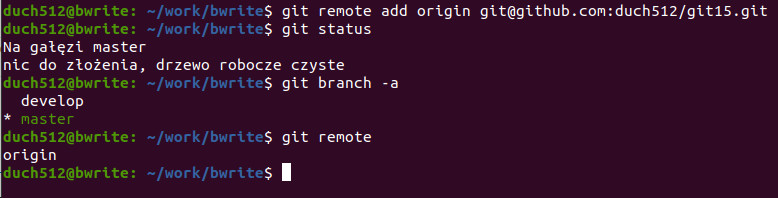
Tym sposobem, przy pomocy komendy git remote add <origin> <adres> dodaliśmy zdalny serwer o nazwie „origin” z adresem „[email protected]:duch512/git15.git” z dostępem po SSH. Teraz autentykacja będzie odbywała się w tle przy użyciu naszego klucza.
Jeśli chcemy logować się w tradycyjny sposób (podając login i hasło przy wykonywaniu zdalnych operacji), powinniśmy podać adres z przedrostkiem HTTPS:
git remote add origin https://[email protected]:duch512/git15.gitJak można zauważyć, zdalny serwer ma swoją nazwę („origin”). Co oznacza, że możemy w jednym lokalnym repozytorium dodać wiele zdalnych repo i wysyłać/pobierać zmiany z którego chcemy. Jednak w typowym projekcie będziemy korzystać tylko z jednego zdalnego repo.
Wysyłanie zmian na serwer
Repozytorium które właśnie utworzyliśmy oraz podpięliśmy jako origin do naszego repo jest całkowicie puste.
Wyślijmy zatem nasze zmiany na serwer przy użyciu komendy git push:
git push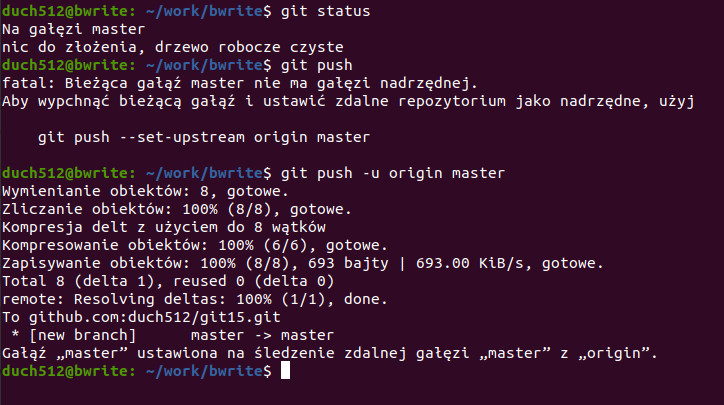
Sprawdzamy stan – jesteśmy na gałęzi master którą chcemy wysłać na serwer. Uruchamiamy komendę git push ale GIT informuje nas, że nasza gałąź nie jest powiązana do żadnej gałęzi w zdalnym repozytorium. To oznacza, że nazwa naszej lokalnej gałęzi nie musi się zgadzać z nazwą gałęzi zdalnej, ale dobrą praktyką jest jednak pozostawianie identycznych nazw. Używamy zatem proponowanego rozwiązania, czyli do komendy dodajemy flagę -u (set upstream), następnie podajemy nazwę zdalnego serwera (origin) oraz nazwę zdalnej gałęzi (jeśli nie istnieje – zostanie stworzona). Po uruchomieniu widzimy informację na temat przesyłania zmian do serwera, m.in. fakt, że została stworzona nowa zdalna gałąź i że nasza lokalna gałąź zaczęła śledzić zdalną gałąź.
Wyślijmy na serwer również naszą drugą gałąź:
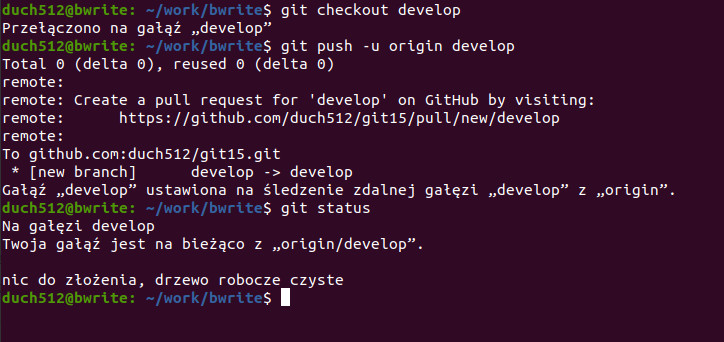
Ponieważ wcześniej wysłana gałaź zawierałą te same commity, przesłane zostały tylko metadane, stąd same zera w statystykach. Oprócz innych standardowych wiadomości dostaliśmy również w bloku „remote” dodatkowe info od GitHuba, który proponuje nam utworzenia czegoś takiego jak pull request po przejściu do przeglądarki. Jest to swego rodzaju narzędzie pomagające zarządzać repozytorium w zespole, gdzie nie każdy ma uprawnienia do wprowadzania zmian do produkcyjnej gałęzi master (co jest zrozumiałe ze względów bezpieczeństwa). Pull request (znany również jako „merge request”) to po prostu prośba o zmergowania zmian z naszego brancha do innego, ważniejszego/stabilniejszego brancha.
Zróbmy jeszcze kilka zmian na gałęzi develop i wyślijmy je na serwer. Pamiętacie nasz Schowek? Czekają tam na nas zmiany które teraz bardzo nam się przydadzą:
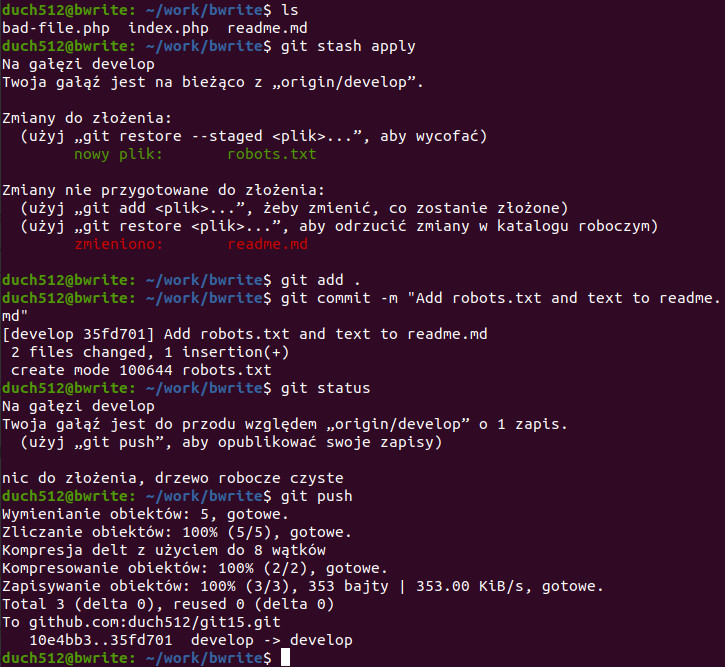
GIT jak zwykle informował nas jakie nastepne kroki możemy wykonać, np. że 1 commit oczekuje na wypchnięcie na serwer. Teraz mamy jeszcze więcej zmian na serwerze 😉
Klonowanie zdalnego repozytorium
Jeśli dołączamy do istniejącego projektu lub chcemy pobrać jakieś repo z internetu, nie musimy najpierw inicjować lokalnego repozytorium. Wystarczy że mamy adres repo (wersję https lub ssh) i użyjemy go w poleceniu git clone.
git clone [email protected]:duch512/git15.gitUtwórzmy sobie nowy katalog i sklonujmy wcześniej wysłane repo (wskazane repo w przykładzie jest publiczne, więc możesz je pobrać na swój komputer – znajdziesz tam wszystkie pliki które są w tym poradniku).
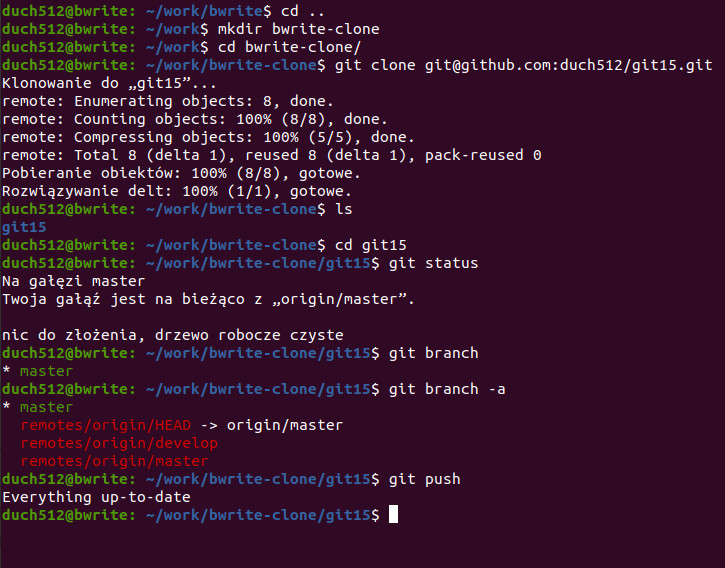
Cofnęliśmy się o jeden katalog w górę i utworzyliśmy nowy, bwrite-clone w którym wykonaliśmy komendę git clone <adres>. GIT pobrał repozytorium z danego adresu, dodatkowo tworząc katalog git15 (tak nazywa się repo) w którym umieszczone jest repozytorium. Po przejściu do niego widzimy że jesteśmy na gałęzi master i jest ona na bieżąco z origin/master – czyli automatycznie śledzimy zdalne repo. Lista lokalnych gałęzi pokazuje tylko gałąź master. Sprawdzamy więc listę branchy z przełącznikiem -a (all), aby zobaczyć również zdalne gałęzie. Próba git push kończy się informacją że wszystko jest aktualne.
Tworzenie nowego katalogu aby mieć w nim kolejny – mało wygodne prawda? Niech zatem git zrobi to za nas! Cofnijmy się do naszego „głównego” katalogu. Podajmy po wcześniej użytej komendzie nazwę katalogu w jakim ma znaleźć się repo:
git clone [email protected]:duch512/git15.git tutorial-git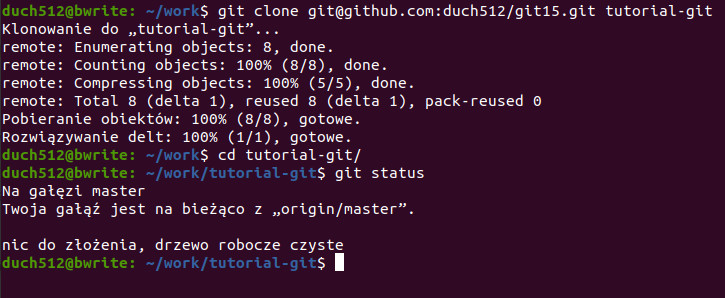
Pobranie zmian z serwera
Trudno będzie pobrać coś „nowego” z serwera na który tylko my coś wysyłamy, dlatego w trakcie punktu o wysyłaniu zmian na serwer zrobiłem jeszcze jednego klona repo, który jest teraz „w tył” z tym co jest na serwerze. Przejdźmy więc na gałąź develop i wykonajmy polecenie git pull które równocześnie pobierze zmiany z serwera (można to zrobić przez git fetch, ale po co? 😉 ) oraz wykona git merge, czyli połączy zdalną zawartość z naszą lokalną. 2 w 1 😉
git pull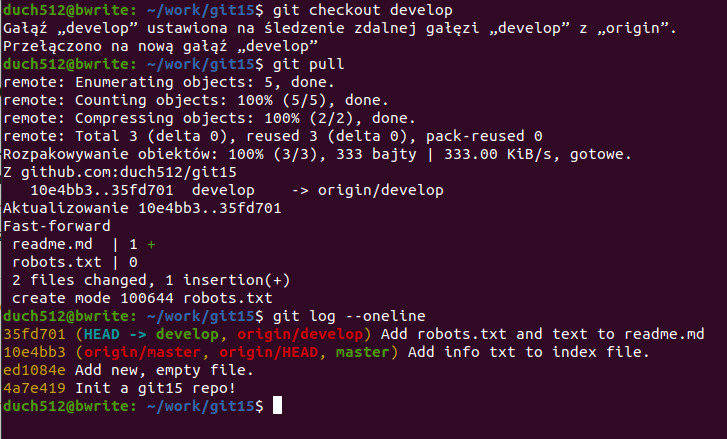
Przełączyliśmy się na gałąź develop – jest to gałąź która występuje na zdalnym repo więc mogliśmy się nia przełączyć i od razu została ustawiona na śledzenie zdalnego odpowiednika. Następnie poleceniem git pull pobraliśmy i scaliliśmy zmiany. git log pokazuje, że jesteśmy na developie, jest aktualny z originem a commit poniżej jest również aktualny do obu masterów.
W rozpoczęciu pracy ze zdalnym repozytorium przyda ci się:
git add remote <origin> <adres>– podpięcie zdalnego repo do lokalnego repogit clone <adres>– skopiowanie istniejącego repo
Podczas pracy ze zdalnym repo najczęściej użyjesz:
git checkout <nazwa– przełączenie się na zdalną gałąź (jeśli istnieje) i śledzenie jej_gałęzi>git pull– pobiera i merguje zmiany (wykonujegit fetchigit mergeze zdalnej gałęzi)git push– wysłanie zmian do zdalnej gałęzigit push -u <origin> <nazwa_gałęzi>– utworzenie zdalnej gałęzi, wysłanie zmian i ustawienie śledzenia zdalnej gałęzi
Słowo na koniec
GIT jest super, prawda? 😉 Mam nadzieję że tak Cię to wciągnęło, że nie masz mi za złe zatytułowanie tego artykułu „GITem w 15 minut”. Przeczytanie a co dopiero przerobienie jego zawartości to troszkę więcej niż zakładany kwadrans, jednak mam nadzieję że taka konkretna porcja wiedzy okaże się przydatna. Oczywiście te kilka akapitów powyżej to naprawdę minimum i warto wiedzieć więcej. Dlatego zachęcam do używania GITa w „pisaniu do szuflady” oraz w codziennej pracy, nawet jeśli pracodawca czy twoi koledzy nie widzą potrzeby pracy z systemem wersjonowania.
Baj!